Courage and Data Literacy Required to Deploy an AI Model and Exploring Design Patterns for AI
Posted July 10, 2021 by Gowri Shankar ‐ 18 min read
Have you ever come across a situation where your dataset is closely linked with human beings and you are expected to optimize certain operations/processes. Does it made you feel anxious? You are not alone, operational optimizations at industrial/business processes are often focused towards minimizing human errors to maximize productivity/profitability - Most likely, depend on machines(to support) rather than fully rely on humans in decision making. These decisions might exacerbate the basic livelihood of certain section of people(often the ones in the bottom of the value chain) involved in the process, if AI is done wrongly.
Writing this post is nothing but walking on thin sheet of ice, I am aware but there are certain things that has to be told. Through this, I am sharing some of my fears and experiences that is seldom spoken, I am sure I am not alone who faced such challenges. This is part of the XAI series where I deviate from methods and maths to a story telling sort. Refer other posts in this series here,
Also, We are exploring 23 Patterns for AI/ML proposed by PAIR with Google. Below image from the famous paper on XAI from DARPA shows, where we stand and where we are heading wrt trust and fairness front.
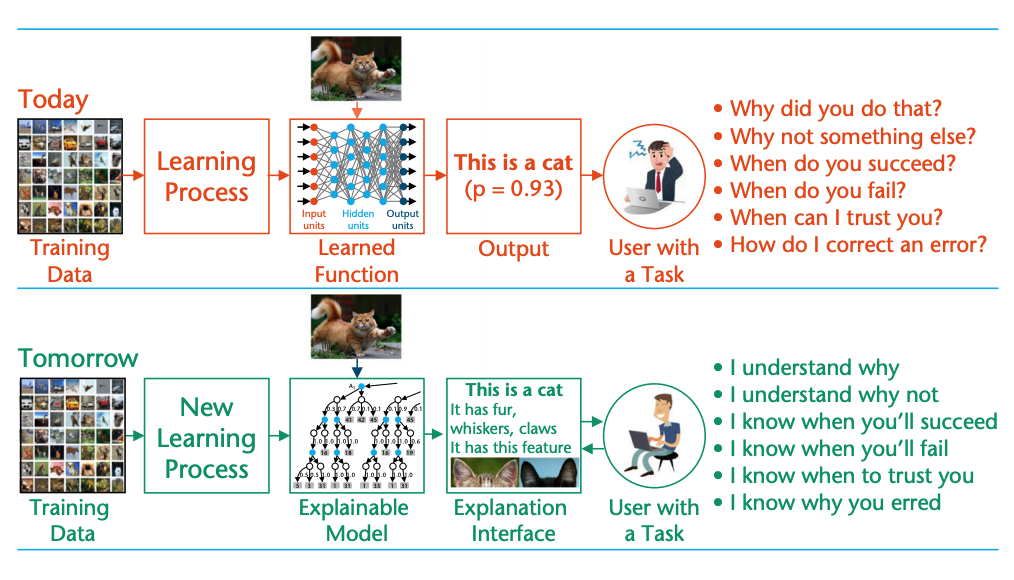
- Image Credits: DARPA’s Explainable Artificial Intelligence Program
Objective
Objective of this post is to explore the following in a no mathy setting
- What is knowledge and how it is related to intelligence?
- Anxiety while deploying an AI model
- Model performance vs explainability
- Data (il)literacy
- Ideas for profitability, introducing Idea Iyyasamy $I^2$
- Listing 23 design patterns proposed by PAIR with Google
Introduction
We live in a world where everything is a click away, knowledge in particular. Having certain level of awareness of something does not make a system/human knowledgeable or intelligent, do they? Few months back, I had a casual chat with a knowledge seeker and asked her, “What is the purpose for your knowledge acquisition?”. She replied, “I should be able to have a conversation with an expert on a particular topic of interest”. Then I asked her, “Do you want to make a tangible work-product out of the knowledge you acquired because knowing to doing is a big leap”. She said, “No, my intent is to have a conversation and nothing beyond”. I do not want to be judgemental but it made me think,
- Is she after true knowledge or creating illusion of being knowledgeable?
- What kind of impact it will cause to the people and surroundings?
- Where it will eventually lead to - if such an individual is given with power of decision making.
I concluded my nearly judgemental thought with the unfortunate fact - ablity to have a conversation is highly rated over ability to create a tangible work product.
We are in the process of building systems that are human like and labelling it intelligent/expert systems with a substandard clarity on what is intelligence and the limitations of knowledges of the known world. We do not bother about known unknowns and unknowns. In such situations, deploying a machine learning model to production is not an easy task for a data professional with certain level of awareness of the unfairness a model potentially can cause to the social and economic well being of the individuals involved. At times, It causes chills because the most efficient AI/ML models are not explainable. On a tough note, I call the models we build are the charlatans we create for our own survival.
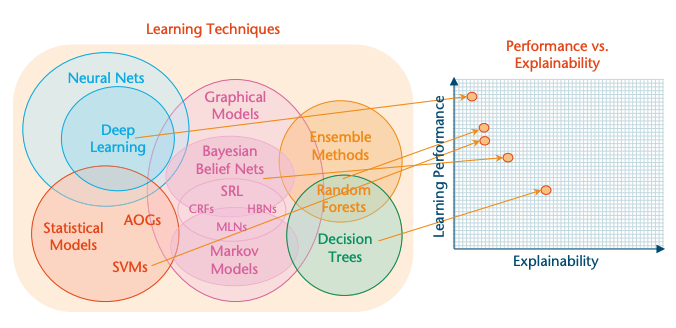
- Image Credits: DARPA’s Explainable Artificial Intelligence Program
Would you believe/trust something that has no explanation? Yes, we do - We call it Faith. Humanity is believing unexplainables since $t_0$ and calling it god(not God) - the omnipotent, omniscient, omnipresent and omnibenevolent principal object of faith. Above DARPA chart shows the deep neural networks are the highly performing AI/ML models with lowest possible explainability, since they are like gods - we have faith on them.
Data Literacy
We cannot deny that the goal is productivity and profitability through the systems that are intend to be deployed in a production environment. Utility of a system(or a human) determines the survival of it or else it slowly lead to an existential crisis with an eventual death of its own. Every technological solution is intertwined with data today, most of the skills like system administration, infrastructure management, security etc are automated and available as few click solutions. With Covid crisis all over the world, a significant jobs under operations had gone obsolete. This level of automation and concept drifts leaves the companies to focus on core business and the data those businesses provide and consume.
Technical professionals are constantly reskilled due to the inherent nature of their work, It is the business people who are expected to understand the nature of the data and the context at which they are used.
– Harvard Business Review
Josh Bersin and Marc Zao in their post Boost Your Team's Data Literacy suggests the following are key skills to be developed among professionals to solve a problem with a data driven approach.
- Ask the right questions
- Understand which data is relevant and how to test the validity of the data they have
- Interpret the data well, so the results are useful and meaningful
- Test hypotheses using A/B tests to see what results pan out
- Create easy-to-understand visualizations so leaders understand the results
- Tell a story to help decision-makers see the big picture and act on the results of analysis
However, the technology teams are always asked with by which date the intelligent system can be deployed rather than the above set lead to data illiteracy at the decision making layer. Further I complain, not many aware how to look at a chart and where to look for right inferencing.
Data and Context Drift - Introducing Idea Iyyasamy $I^2$
Selling technology was fashionable once and today it is AI - using jargons like predictive, prescriptive and state of the art makes the powerpoint salesmen looks not only sexy but superior. Once, I was approached by an enthusiast who wanted to build an expert system that predicts the quantity of sales returns in a retail business. Our enthusiast is enthusiastic about anything and everything of the world, you call it social justice or super-natural pseudo-coding - He has an opinion and ensure his opinion is imbibed in everyone’s heart and soul. Let us call him Idea Iyyasamy($I^2$) because of his sheer energy to create ideas and have absolutely all(no) quirks to convert it into a work-product$^1$. $I^2$s are popular among masses due to their natural ability to bring hope(false) and prosperity(fake) by rendering an illusion in front of their audience. With his sagacious outlook and exhilarating oration, $I^2$ bagged an investment for building an AI solution and the execution responsibility is bestowed upon me.
- $I^2$: Shankar, we have to predict the returns quantity of certain retail business - It has tremendous market value.
- $Me$: Sounds interesting - Would you please elaborate the problem in detail?
I have my inner-demon, It often get excited when it hears challenging problems to solve
- $I^2$: We have to identify the SKUs of a retail business which are likely to get returned, by identifying them we can stop shipping and save the cost of logistics.
- $Me$: Wow, excellent idea - It looks like SKU returns are function of buyer’s buying and returning pattern.
My inner-demon already started assessing whether it is a classification(return/not a return) problem or regression(quantity of returns of an SKU for a period) one
- $I^2$: No, we have to identify this from the returns pattern
- $Me$: Oh, OK - It looks like buying pattern and user attributes are more appropriate but we can march half way if the product is consistently returned by the consumers
My inner-demon is assertive now, It identified a gap in the whole process. Without the intervention of the consumer we have to stop the shipment
- $I^2$: Yes, you got me - now we are in the same page. Let us build a prototype
quicklyand demonstrate to a bunch of CPG companies and Mr. No Brainer will take us through the bureaucracy.
Now my inner-demon transformed to an inner-puppy, this transformation often happens when it hears jargons like quick, rapid development etc.
- $Me$: I would like to do an exploratory data analysis, would you please share the
returns dataand theconsumer purchasing patterns - $I^2$: No, we do not have access to any of the data. We have to create synthetic data to build and demonstrate, our tech stack should be spreadsheet.
I go speechless and the puppy inside me starts transforming into a demon back using a sophisticated basis vector - thinking, Is it a reinforcement learning problem.
How to explain Concept and Data Drift?
On a different dimension, If you notice closely - I bumped into a new problem, How to explain Concept and Data drift to an audience that thinks intelligence can be built without knowledge(data). Please note, $I^2$s are the ones adored, believed and celebrated because they truly bring hope(false) and prosperity(fake) at the expense of somoene’s ignorance.
1 - $I^2$s approach to solve an object detection problem was something made me trip down from my seat, It is a deep topic beyond the scope of this article and to be written in a whole new post with full focus.
Math or No Math
It is a must to have a deeper understanding of the mathematical intuition behind every aspect of the model building process. Following are the key areas of Math that is intertwined to accomplish a sophisticated AI system,
- Linear Algebra
- Probability
- Statistics and
- Calculus
We have discussed these topics individually and collectively in our Math for AI/ML Series and we will be discussing much more on this front in the future.
We seek math to our help/resuce when we start asking ourselves Why do well tested and deployed models fail?, There are 2 key reasons and they make complete sense only when empirically analyzed,
- Inability to identify and employ counterfactuals into the models and
- The concept and data drift due to constant change of the universe
Employing Counterfactuals
We cannot truly employ counterfactuals into a model, i.e. We do not have access to all influencers and even if we have, we do not have sufficient energy to account those influencers. For e.g. If we had anticipated Covid crisis during the month of Feb, 2020, we would have built a model with counterfactuals to cope with the crisis. Please refer,
Left with Data then?
Causal reasoning and What-If analysis are critical and drift in the data against the concepts are to be measured empirically and monitored. Some of the widely accepted methods are
- Model Agnostic Methods: Models are considered black boxes and model agnostics schemes are employed to interpret the results
- Partial Dependence Plots
- Accumulated Local Effects
- Permutation Feature Importance
- Local Surrogates (LIME)
- Shapely Values (SHAP)
- Model Specific Methods: Interpretation and Measurements inherently implemented while building the model. e.g. Temporal Fusion Transformers(TFT) for time series forecasting
For deeper dive, refer Attribution and Counterfactuals - SHAP, LIME and DiCE
In layman’s language - We are dealing with data of multi-dimensions, one cannot judge a model’s efficacy through few variable - It is beyond his/her ability to perceive large number of influencers. Hence we seek math to summarize and simplify to fit our comprehension and machines to deal with raw observations.
23 Design Patterns for AI & ML
Artificial Intelligence may be small component of an entire software system but it will be the most powerful one that has no correlation to the size. AI solutions adds significant impact to the value of the whole system. For example we can identify toxic content during creation phase, classify pornographic materials while uploaded, catch copyright breaches and there is no limit to how creatively an AI can be used. However, If AI is done wrongly - It will cause damages to an individual and the social system. For example, industry optimzations might cause job losses, unfair models towards ethnicity, gender etc will be discriminative to certain section of people and it is a long list that makes us to focus towards XAI.
Our problems are multitude, while we work on explanations and interpreation to fairness to counterfactuals - It is imminent to set certain guidelines and proesses to avoid adversarial impacts. In this section, we shall discuss 23 design patterns for AI and ML coined by PAIR - People + AI Research from Google.
People + AI Research (PAIR) is a multidisciplinary team at Google that explores the human side of AI by doing fundamental research, building tools, creating design frameworks, and working with diverse communities.
We believe that for machine learning to achieve its positive potential, it needs to be participatory, involving the communities it affects and guided by a diverse set of citizens, policy-makers, activists, artists and more.
– People + AI Research (PAIR)
Overview of the Patterns
Patterns are broadly tagged under 8 different questions, each has its own set of patterns and they are repeated based on the context of the question. The questions are
- How do I get started with human centered AI?
- When and how should I use AI in my product?
- How do I onboard users to new AI features?
- How do I explain my AI system to users?
- How do I responsibly build my dataset?
- How do I help users build an calibrate trust in my product?
- What’s the right balance of user control and automation?
- How do I support users when something goes wrong?
We shall review all 23 patterns in the subsequent sections and make a commentary on them.
The Patterns
The following list of patterns can be referred at Patterns for more clarity.
Determine if AI adds value
AI is better at some things than others. Make sure that it’s the right technology for the user problem you’re solving.
Let us take a hypothetical situation of a salesman visiting his customers everyday for the last 15 years and selling his commodities. He knows his customer and his needs, No better AI can replace him unless there is a drastic change in his selling patterns. However, If he retires or replaced by another salesman - There is a need for data driven assistance to ensure continuance and optimization.
Set the right expectations
Be transparent with your users about what your AI-powered product can and cannot do.
Many of us came across this problem, Data literacy - AI models are probabilistic and they are tend to give unexpected/incorrect outputs. General tendency among most is to see AI/ML solutions as just another deterministic software solutions. This is augmented by the auro of $I^2$s and Mr.No Brainers by in large.
Explain the benefit, not the technology
Help users understand your product’s capabilities rather than what’s under the hood.
I was once offered a job and the recruiting manager could’nt explain the problem to detail but he was sure it should be solved using Deep Learning. I have to turn the offer down. He failed to deliver his promises to his employer and put everyone else involved in jeopardy. Basically, my acquaintance sold DNN to the stakeholders because DNNs are god like, unexplainable and uninterpretable. Faith always sells.
Be accountable for errors
Understand the types of errors users might encounter and have a plan for resolving.
Being accountable is a cultural thing, There are many leaders who has the courage to take accountable for their failures. Rest blame it on NA(Not Applicables) who is an incapable/survivor out of sympathy rather than his contributions.
Invest early in good data practices
The better your data planning and collection processes, the higher the quality your end output.
I noticed experienced engineers run update/delete scripts directly on the production systems because of holes in the validation process during ingestion. This is a classic case of undervaluing data integrity, poor documentation lead to un-uniform data ingestion endpoints. i.e. If we do not invest early on good practices, we will never deliver a quality end product.
Make precision and recall tradeoffs carefully
Determine whether to prioritize more results or higher quality results based on your product’s goals.
Most of us cannot think beyond accuracy, a loss as a metrics is far-fetched. Precision and recall are beyond the scope, invest on data literacy.
Be transparent about privacy and data settings
From initial onboarding through ongoing use, continue to communicate about settings and permissions.
In most of the organizations, people and groups work in silos - Bringing them all together is a big challenge due to ego, internal rivalry/secrecy. Data literacy is again have an effect due to culture and diversity.
Make it safe to explore
Let users test drive the system with easily reverisible actions
Every action in a software system should be reversible, maintaining history and logs of every user action is critical before deploying an expert system to production. This is critical because the recommendations are personalized and it is eventually going to affect the livelihood of individual and the society he/she is influencing.
Anchor on familiarity
As you onboard users to a new AI-driven product or feature, guide them with familiar touchpoints
Ideally the AI system should seemlessly integrate with the existing system without much impact on the user experience. Large organizations invest significant on ensuring this at the planning stage itself. For example Google uses AI in almost every service they offer but we seldom notice an impact.
Add context from human sources
Help users appraise your recommendations with input from third-party sources
Vet the quality of your model output through 3rd party groups, communities and experts.
Determine how to show model confidence, if at all
If you decide to show model confidence, make sure it’s done in a way that’s helpful to your user.
Displaying model confidence helps the users to make right decisions. However, confidence intervals should be displayed in tandem with the context of the information.
Explain for understanding, not completeness
Focus on giving your users the information they need in the moment, rather than a full run-down of your system.
Recommendations are given to the end user to support his decision making, this is the place where explainability measures and causal reasonings can be displayed.
Go beyond in-the-moment explanations
Help users better understand your product with deeper explanations outside immediate product flows
Automate more when risk is low
Consider user trust and the stakes of the situation when determining how much to automate
Let users give feedback
Give users the opportunity for real-time teaching, feedback and error correction
Let users supervise automation
Maintaining control over automation helps users build comfort and correct when things go wrong.
Automate is phases
Progressively increase automation under user guidance.
Give control back to the user when automation fails
Give your users a way to move forward even when the system fails or offers poor quality output.
AI systems are tend to fail due to their probabilistic nature, the easiest path forward is to let the user take over from the auto mode. For e.g. Auto-pilot to manual mode in self-driving cars.
Design for your data labelers
Make sure that data labelers have well designed tools and workflows.
For supervised learning, accurate data labels are a crucial ingredient to achieve relevant ML output. Labels can be added through automated processes or by people known as labelers.
Labeling tools range from in-product prompts to specialized software. If you’re working with labelers, it’s worth investing time upfront in selecting or designing the tools, workflows, and instructions. The best way to do this is often in collaboration with the labelers themselves.
Actively maintain your dataset
Maintain the quality of your product experience by proactively maintaining the quality of your data
Data has to be maintained and tagged before injesting to train a model. Updates and deletes are to be logged and history of changes are to be maintained.
Learn from label disagreements
Understand differences in how labelers interpret and apply labels to prevent problems later on.
When you encounter labels that are “messy," unexpected, or hard to reconcile, don’t categorically discard them as “noisy." Take time to investigate whether issues with labeler tools, workflows, instructions, or overall data strategy may be leading to such issues with labels.
Embrace noisy data
The real world is messy! Expect the same from the data that you gather.
Noise in dataset is imminent because of a simple reason concept and data drift. Everthing changes, the only constant thing in this universie is change.
Get input from domain experts as you build your dataset
Building partnerships with domain experts early can help reduce iterations on your dataset later on.
Sustained interactions with domain experts during the project lifecycle is critical for the success of the project. For e.g. Impact of having a radiologist while working on medical imaging dataset adds tremendous value to the final outcome. Similarly, an accountant is critical while working on a financial data.
Inference
It is my nature to go deeper into any task I undertake and quite attentive to details. Some of the AI/ML research I have conducted often put me in an anxious state due to the fact, how close a decision taken by a machine will impact livelihood of individuals involved and the society at the stake. These design patterns coined by PAIR is not anything new to a data professional but consummating and evangelizing is critical to avoid those anxious moments, thanks to Google. When we are in crisis, we can tag our issue under a pattern of right fit and seek help from the community for a fix/solution. Further, we saw the set of personas involved in achieving a Responsible AI. Formalizing AI in the form of Design Patterns is an important milestone in the quest for avoiding any adversial effects in the future.
References
- Boost Your Team’s Data Literacy by Josh Bersin and Marc Zao, 2020
- PAIR PAIR with Google
- Patterns PAIR with Google
- About David Weinberger
- The What-If Tool: Interactive Probing of Machine Learning Models by Wexier et al, 2020
- Bias in Criminal Risk Scores Is Mathematically Inevitable, Researchers Say by Julia Angwin and Jeff Larson, 2016
- Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI by Arrieta et al
- DARPA’s Explainable Artificial Intelligence Program by David Gunning and David Aha, 2019
- Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV) by Kim et al, 2018
- Explainable AI for Trees: From Local Explanations to Global Understanding by Lundberg et al, 2019
– David Weinberger, Writer in Residence at PAIR