Human Capital Meets Token Capital - How I Cut My Claude API Costs Before They Bankrupted Me
Posted June 27, 2026 by Gowri Shankar ‐ 12 min read
Every failed prompt. Every let's try a different approach. Every hallucination. Every beautifully reasoned answer that turned out to solve a completely different problem. Somewhere during six blissfully focused hours of building a Jupyter notebook, Claude happily consumed two hundred dollars' worth of my optimism. I topped up my credits, convinced I'd learned my lesson. An hour later, they were gone too. At that point I stopped debugging my notebook and started debugging my spending habits.

RALPH Loop: Building Self-Improving AI Systems WITHOUT Claude
Posted May 2, 2026 by Gowri Shankar ‐ 16 min read

How I Cut My Infrastructure Costs by 35% Overnight - A Startup Survival Checklist
Posted October 5, 2025 by Gowri Shankar ‐ 10 min read

When Krishna Teaches, Arjuna Listens - But What If They’re Both Within Us and With Us (Perplexity)?
Posted April 20, 2025 by Gowri Shankar ‐ 4 min read

Reflexive by Default: The Role of Human Beings in an AI-Driven World
Posted April 13, 2025 by Gowri Shankar ‐ 8 min read

AI as a Business Partner: Validating My Healthcare App Idea using GPT-4o
Posted March 23, 2025 by Gowri Shankar ‐ 4 min read

Pair Programming with an AI: Debugging Profile Picture Uploads with Claude-3.7
Posted March 2, 2025 by Gowri Shankar ‐ 9 min read

Exploring the Randian Hero: A Deep Dive into Ayn Rand's Characters
Posted May 18, 2024 by Gowri Shankar ‐ 9 min read

Evaluating Large Language Models Generated Contents with TruEra’s TruLens
Posted March 17, 2024 by Gowri Shankar ‐ 12 min read

The 40 rules of love
Posted December 23, 2023 by Gowri Shankar ‐ 41 min read

Airflow Trigger Rules for Building Complex Data Pipelines Explained, and My Initial Days of Airflow Selection and Experience
Posted May 1, 2022 by Gowri Shankar ‐ 9 min read
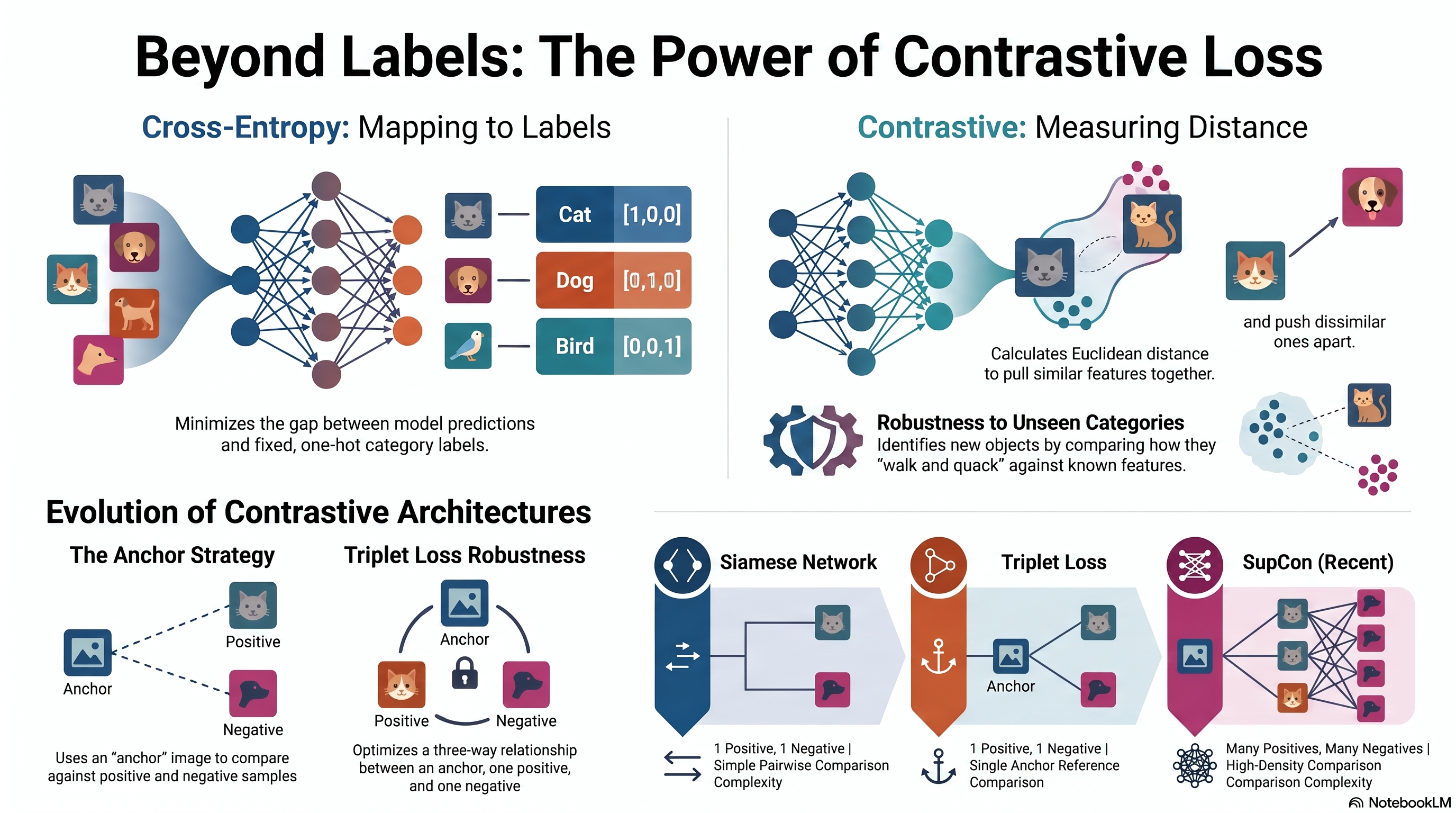
Introduction to Contrastive Loss - Similarity Metric as an Objective Function
Posted January 30, 2022 by Gowri Shankar ‐ 6 min read

Temperature is Nothing but Measure of Speed of the Particles at Molecular Scale - Intro 2 Maxwell Boltzmann Distribution
Posted January 23, 2022 by Gowri Shankar ‐ 7 min read

The Best Way to Minimize Uncertainty is NOT Being Informed, Surprised? Let us Measure Surprise
Posted January 14, 2022 by Gowri Shankar ‐ 6 min read

3rd Wave in India, Covid Debacle Continues - Let us Use Covid Data to Learn Piecewise LR and Exponential Curve Fitting
Posted January 7, 2022 by Gowri Shankar ‐ 8 min read

Ever Wondered that Voice is from a Human Being or Created by a Computer? Revisiting Normalizing Flows
Posted December 31, 2021 by Gowri Shankar ‐ 8 min read
Transformers Everywhere - Patch Encoding Technique for Vision Transformers(ViT) Explained
Posted December 24, 2021 by Gowri Shankar ‐ 8 min read

Understanding Self Attention and Positional Encoding Of The Transformer Architecture
Posted December 17, 2021 by Gowri Shankar ‐ 9 min read
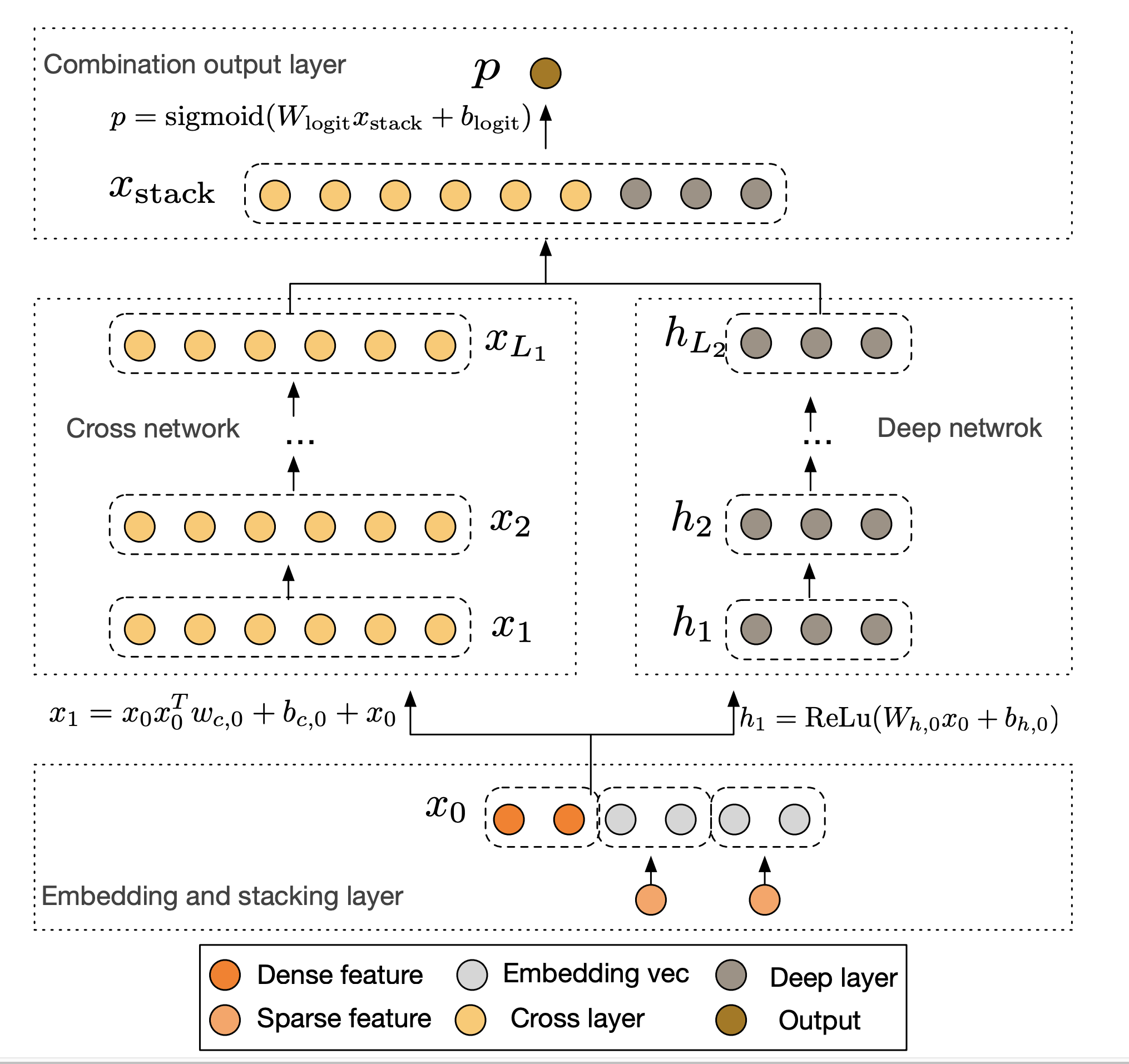
TFRS for DLRMs At Enterprise Scale - A Practical Guide to Understand Deep and Cross Networks
Posted December 10, 2021 by Gowri Shankar ‐ 10 min read
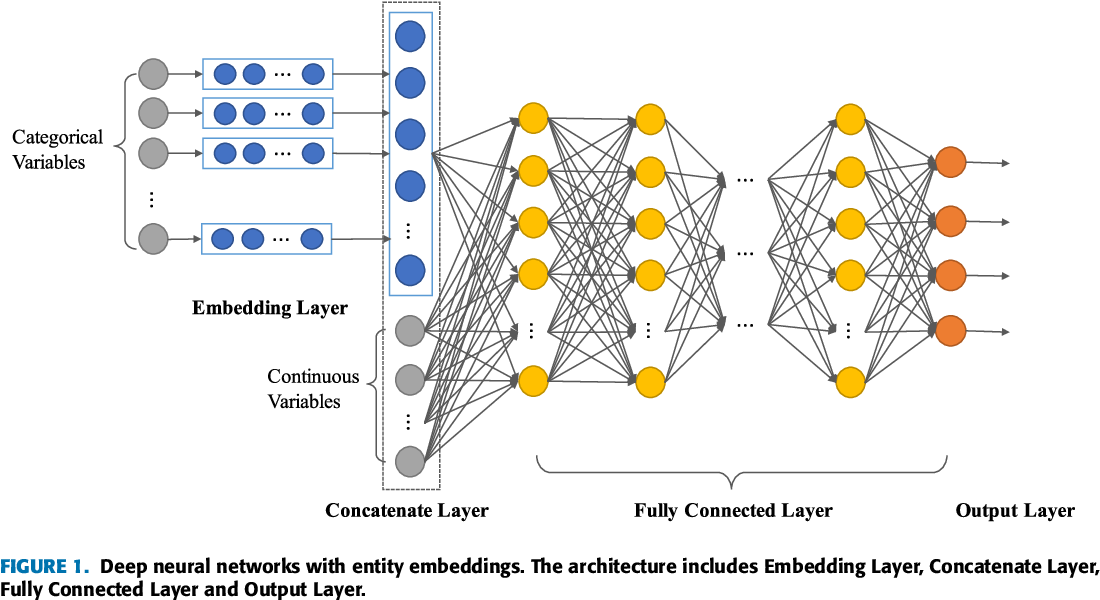
Quotient-Remainder Embedding, Dealing With Categorical Data In A DLRM - A Paper Review
Posted December 3, 2021 by Gowri Shankar ‐ 7 min read
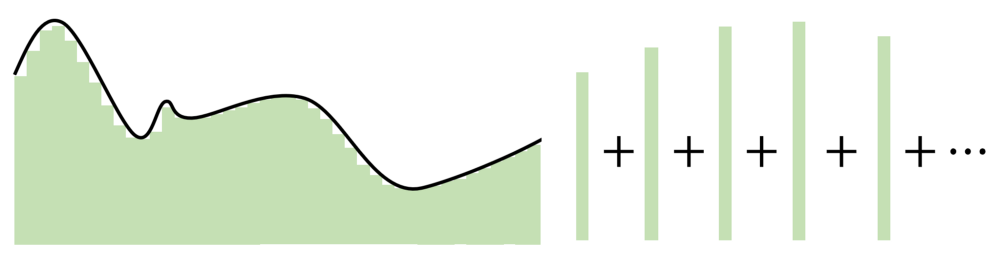
That Straight Line Looks a Bit Silly - Let Us Approximate A Sine Wave Using UAT
Posted November 29, 2021 by Gowri Shankar ‐ 4 min read
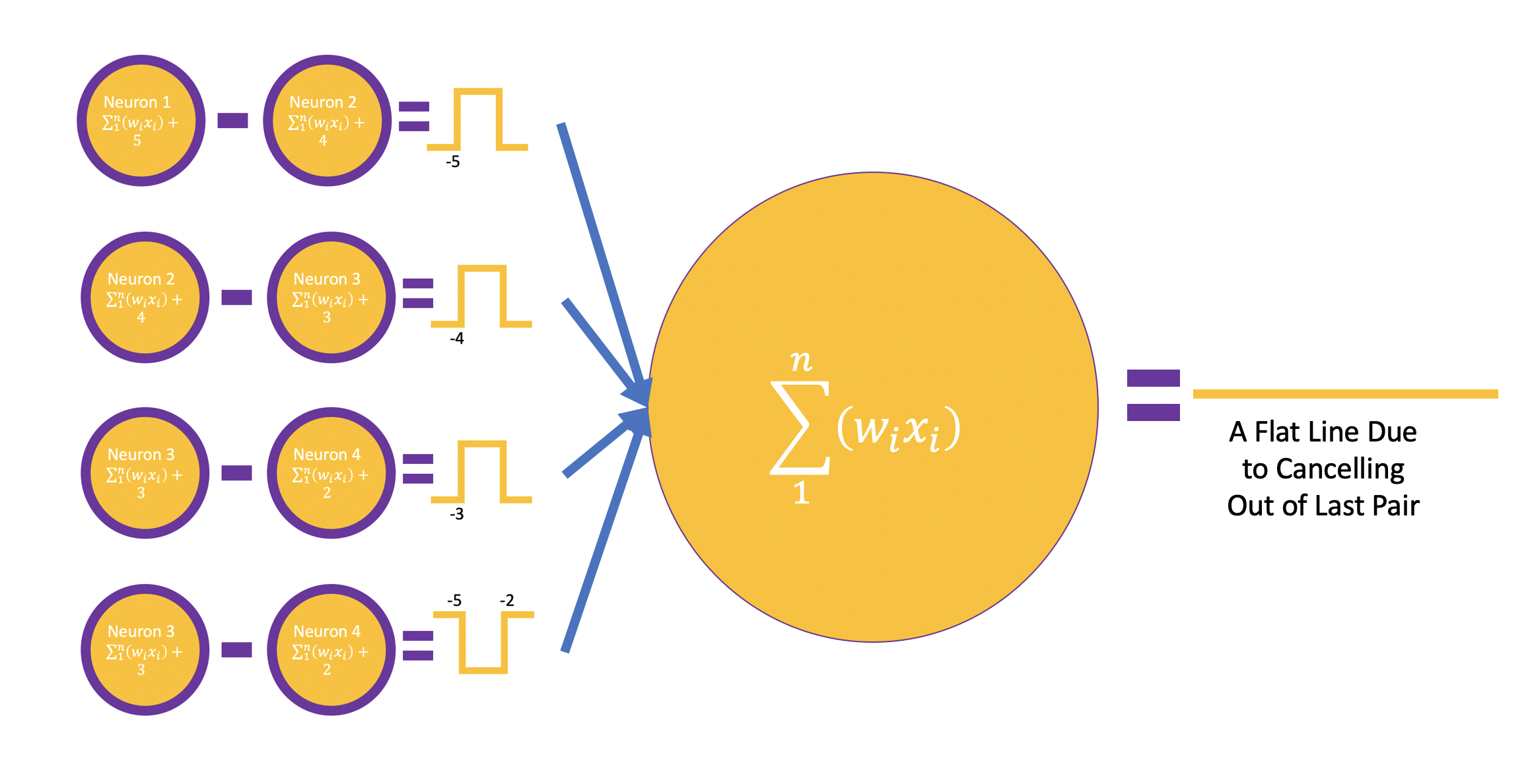
Do You Know We Can Approximate Any Continuous Function With A Single Hidden Layer Neural Network - A Visual Guide
Posted November 27, 2021 by Gowri Shankar ‐ 11 min read

Deep Learning is Not As Impressive As you Think, It's Mere Interpolation
Posted November 24, 2021 by Gowri Shankar ‐ 14 min read
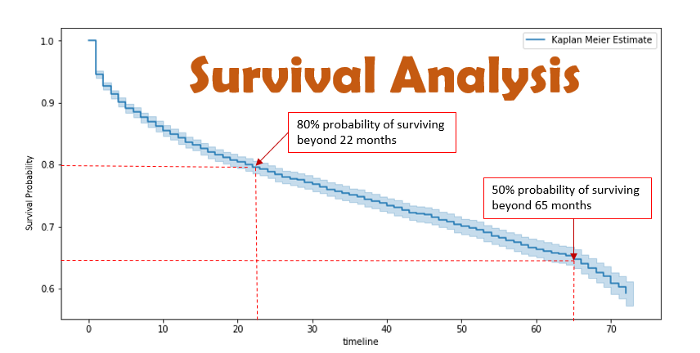
Survival Analysis using Lymphoma, Breast Cancer Dataset and A Practical Guide to Kaplan Meier Estimator
Posted November 20, 2021 by Gowri Shankar ‐ 9 min read

Dequantization for Categorical Data, Categorical NFs via Continuous Transformations - A Paper Review
Posted November 13, 2021 by Gowri Shankar ‐ 9 min read

Bijectors of Tensorflow Probability - A Guide to Understand the Motivation and Mathematical Intuition Behind Them
Posted November 7, 2021 by Gowri Shankar ‐ 11 min read
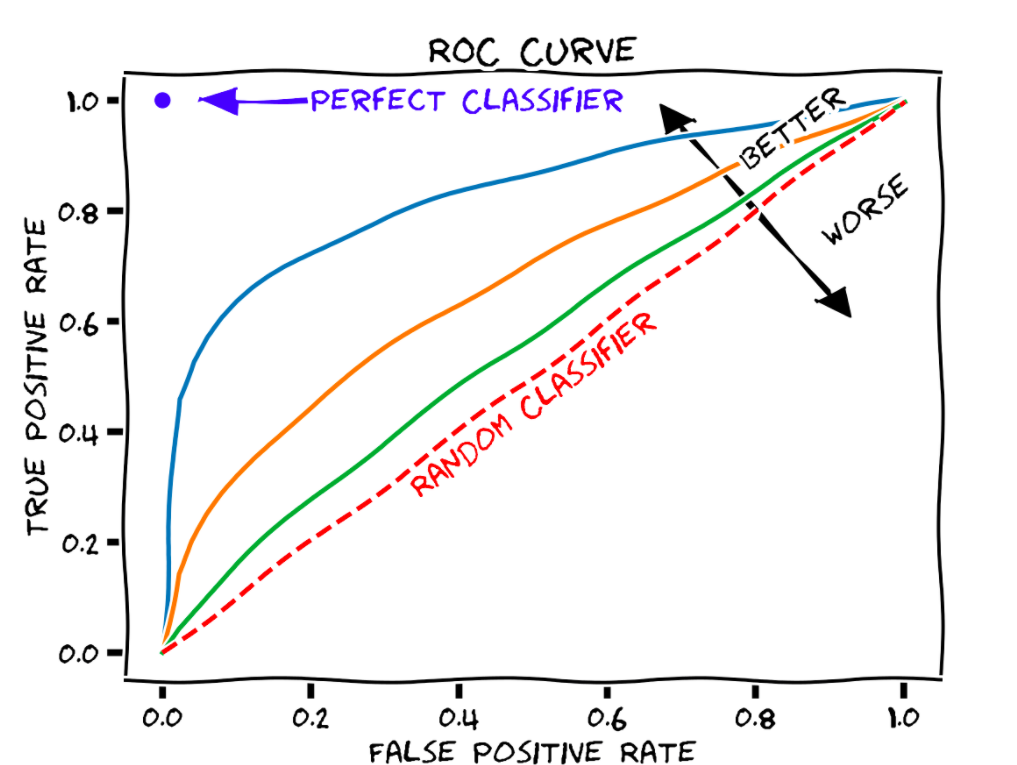
Metrics That We Measure - Measuring Efficacy of Your Machine Learning Models
Posted October 30, 2021 by Gowri Shankar ‐ 7 min read
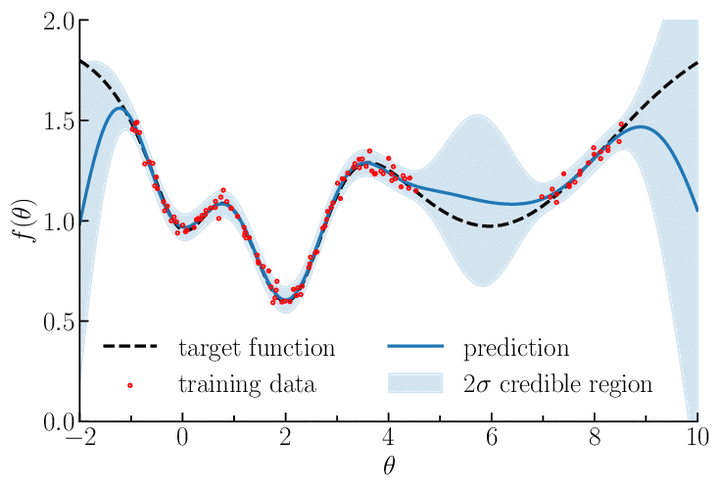
Gaussian Process and Related Ideas To Kick Start Bayesian Inference
Posted October 24, 2021 by Gowri Shankar ‐ 7 min read
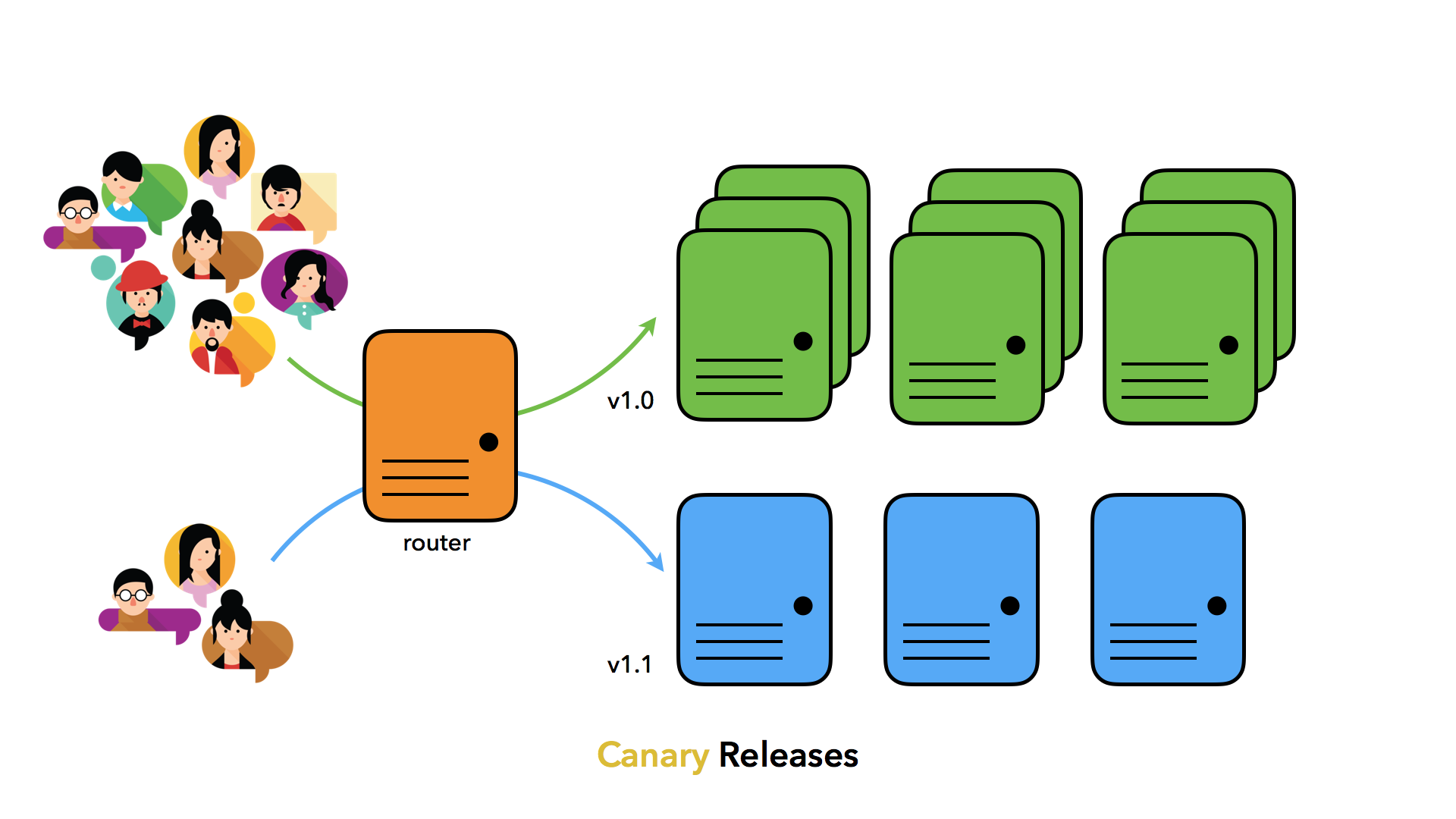
Istio Service Mesh, Canary Release Routing Strategies for ML Deployments in a Kubernetes Cluster
Posted October 16, 2021 by Gowri Shankar ‐ 13 min read
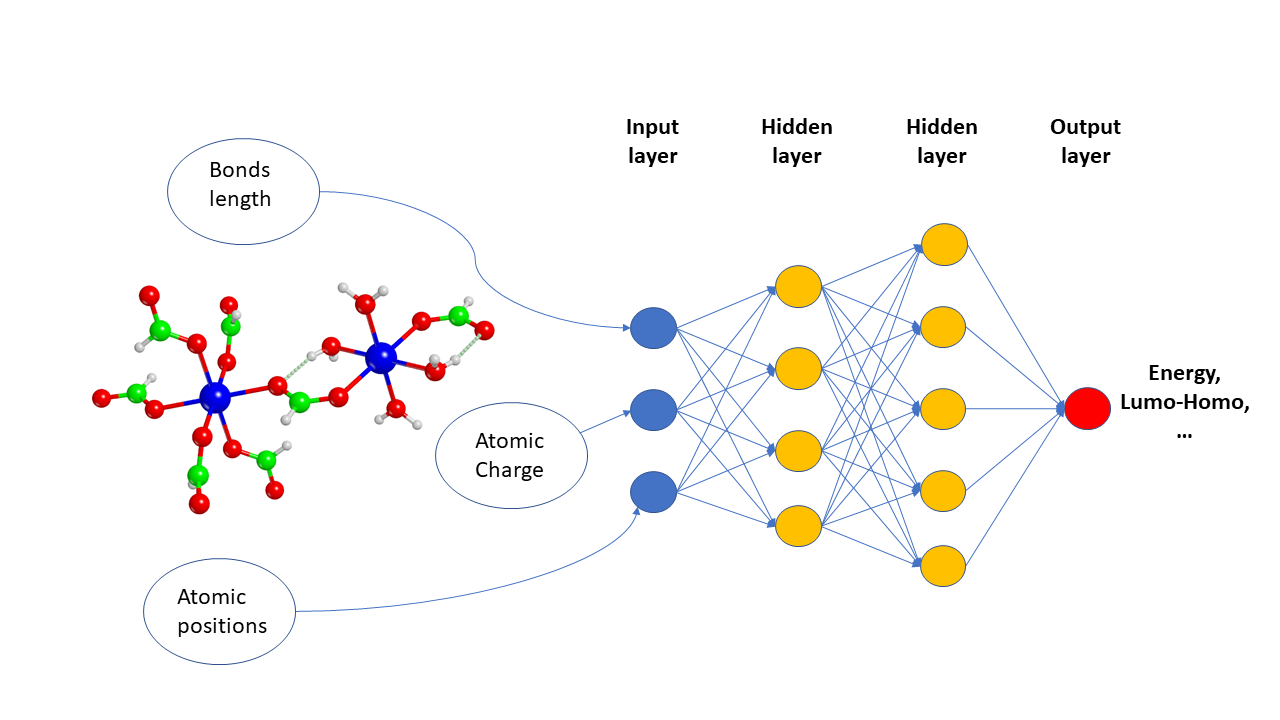
Atoms and Bonds 2 - ML for Predicting Quantum Mechanical Properties of Organic Molecules
Posted October 8, 2021 by Gowri Shankar ‐ 10 min read
Atoms and Bonds - Graph Representation of Molecular Data For Drug Detection
Posted October 2, 2021 by Gowri Shankar ‐ 15 min read
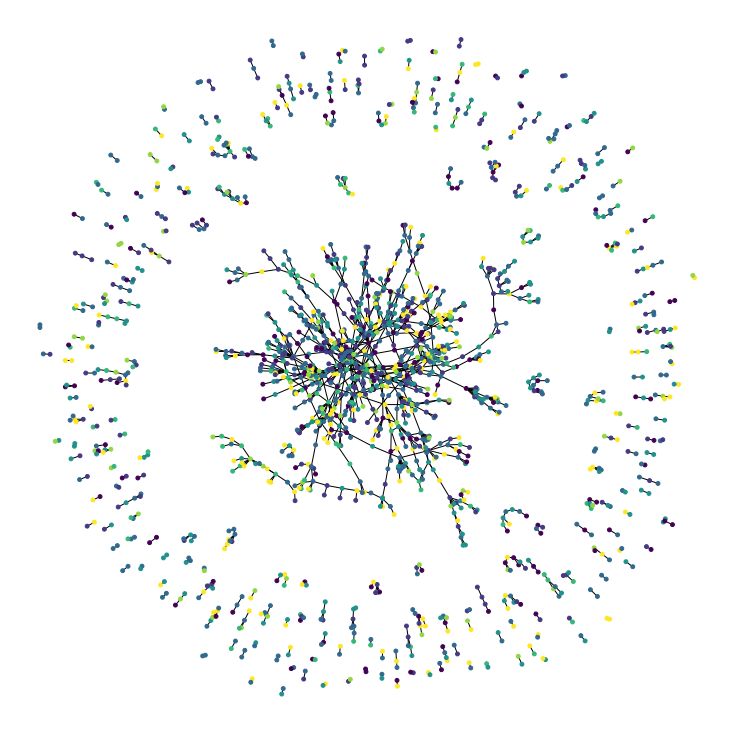
Graph Convolution Network - A Practical Implementation of Vertex Classifier and it's Mathematical Basis
Posted September 25, 2021 by Gowri Shankar ‐ 10 min read

Introduction to Graph Neural Networks
Posted September 19, 2021 by Gowri Shankar ‐ 9 min read
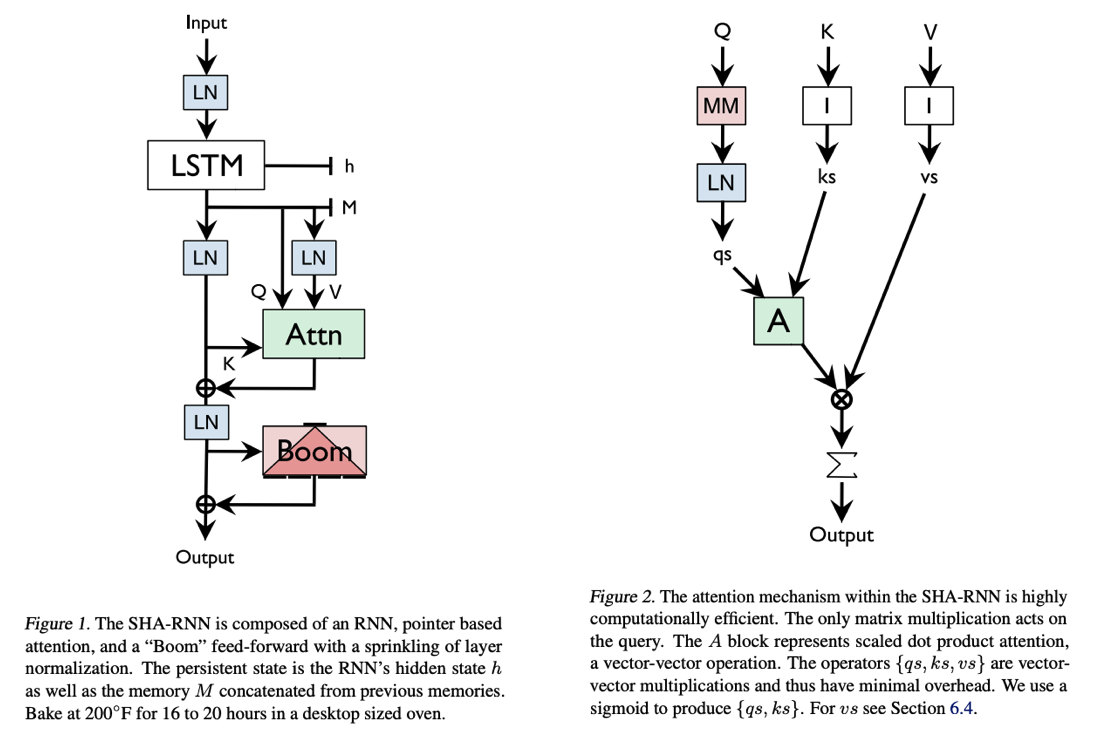
Relooking Attention Models, SHA-RNN Overview, gMLP Briefing and Measuring Efficacy of Language Models through Perplexity
Posted September 11, 2021 by Gowri Shankar ‐ 10 min read

Gossips and Epicenter of Emotions for our Existence - Study on Anatomy of Limbic System
Posted September 5, 2021 by Gowri Shankar ‐ 9 min read

Methodus Fluxionum et Serierum Infinitarum - Numerical Methods for Solving ODEs Using Our Favorite Tools
Posted August 28, 2021 by Gowri Shankar ‐ 8 min read
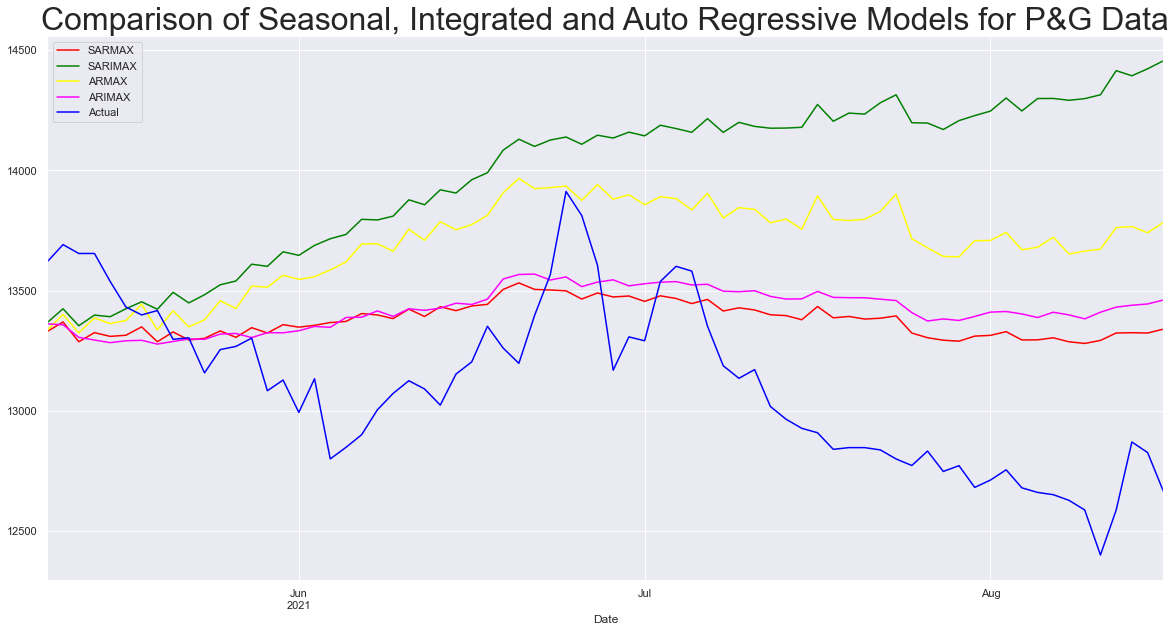
A Practical Guide to Univariate Time Series Models with Seasonality and Exogenous Inputs using Finance Data of FMCG Manufacturers
Posted August 21, 2021 by Gowri Shankar ‐ 10 min read

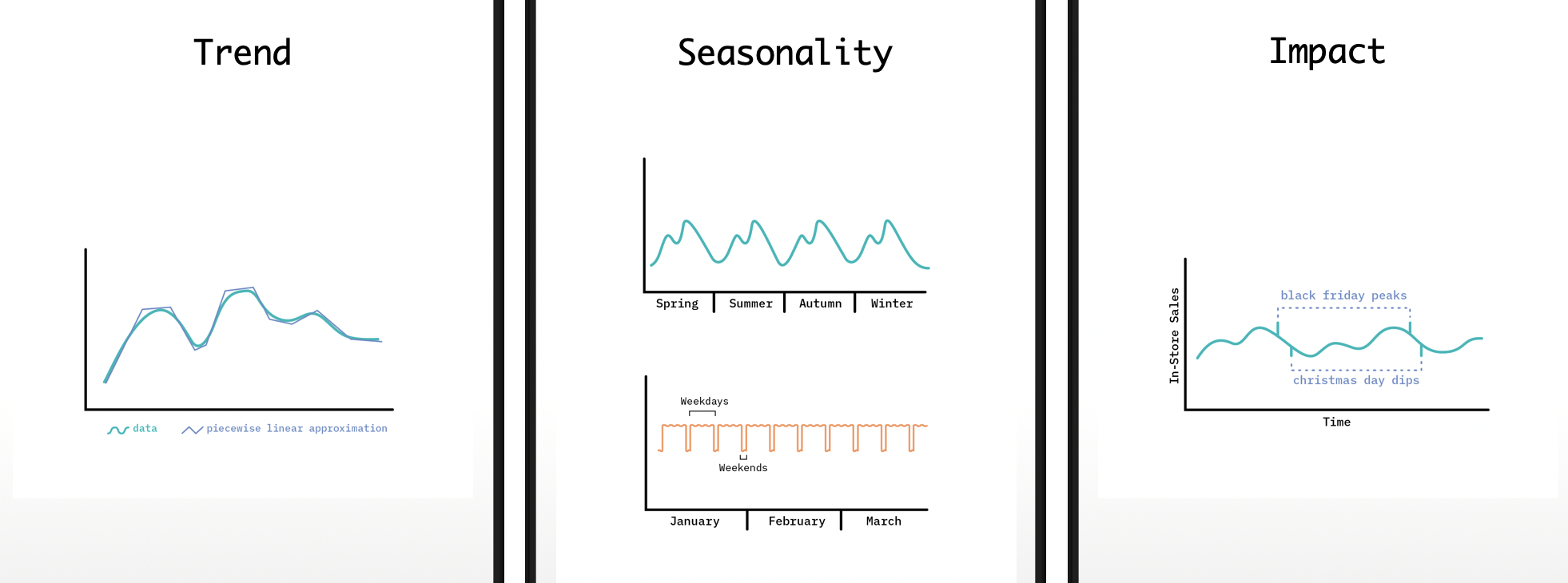
Trend, Features of Structural Time Series, Mathematical Intuition Behind Trend Analysis for STS
Posted August 14, 2021 by Gowri Shankar ‐ 6 min read

Fourier Series as a Function of Approximation for Seasonality Modeling - Exploring Facebook Prophet's Architecture
Posted August 8, 2021 by Gowri Shankar ‐ 8 min read
Structural Time Series Models, Why We Call It Structural? A Bayesian Scheme For Time Series Forecasting
Posted August 1, 2021 by Gowri Shankar ‐ 7 min read

Blind Source Separation using ICA - A Practical Guide to Separate Audio Signals
Posted July 24, 2021 by Gowri Shankar ‐ 6 min read
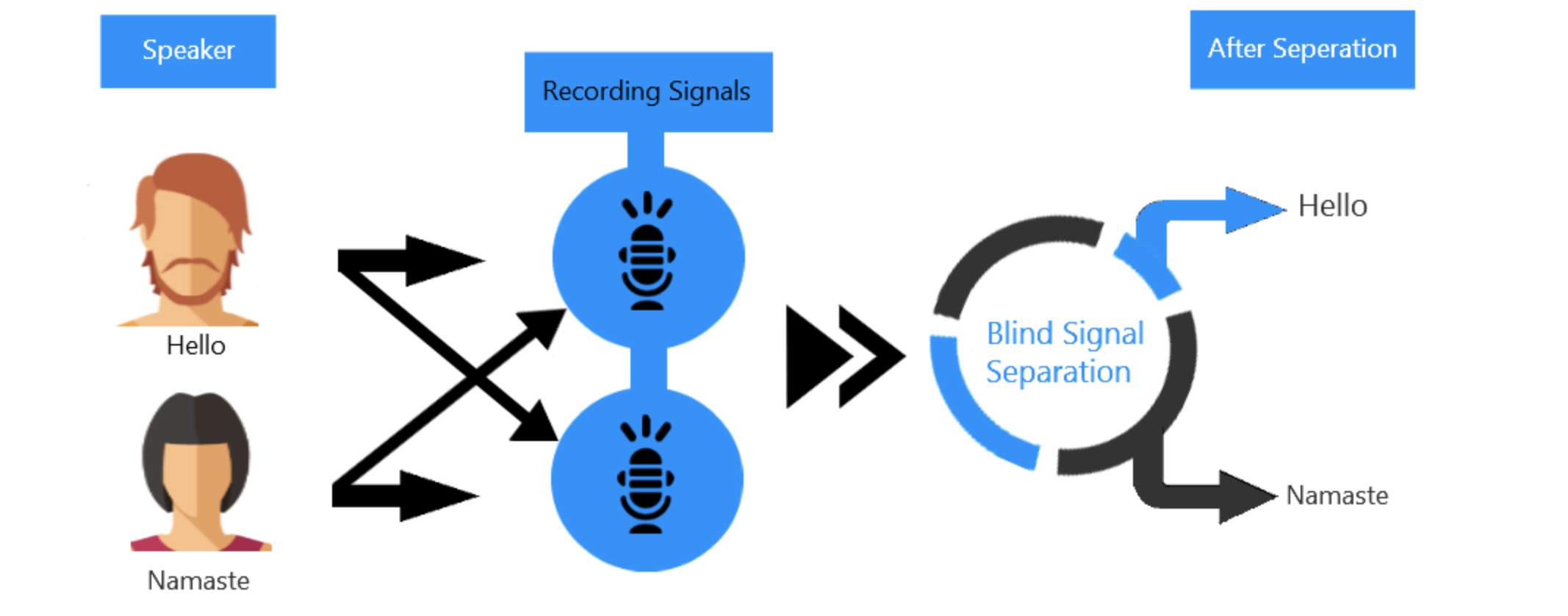
Cocktail Party Problem - Eigentheory and Blind Source Separation Using ICA
Posted July 18, 2021 by Gowri Shankar ‐ 13 min read
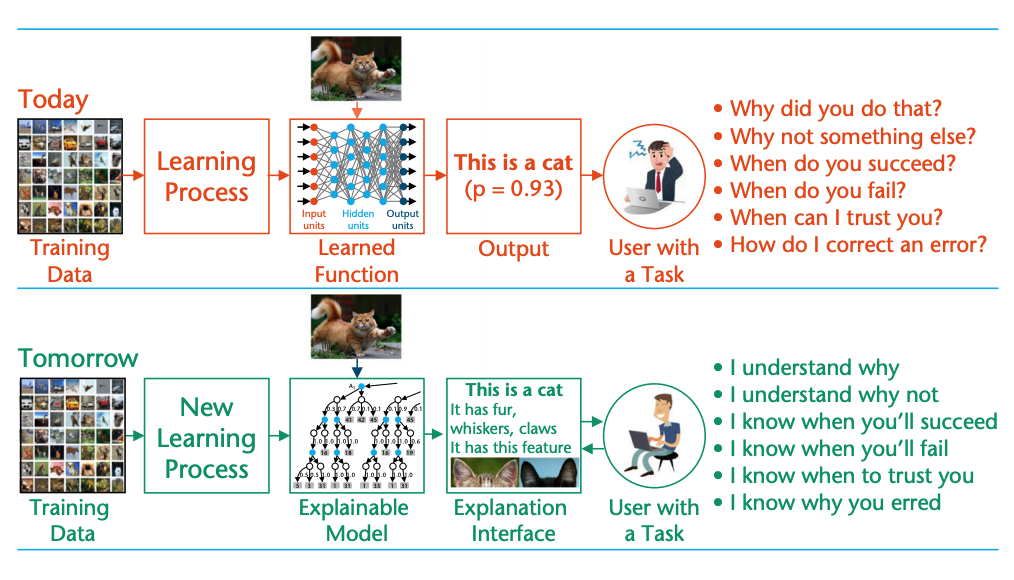
Courage and Data Literacy Required to Deploy an AI Model and Exploring Design Patterns for AI
Posted July 10, 2021 by Gowri Shankar ‐ 18 min read
Eigenvalue, Eigenvector, Eigenspace and Implementation of Google's PageRank Algorithm
Posted July 3, 2021 by Gowri Shankar ‐ 8 min read
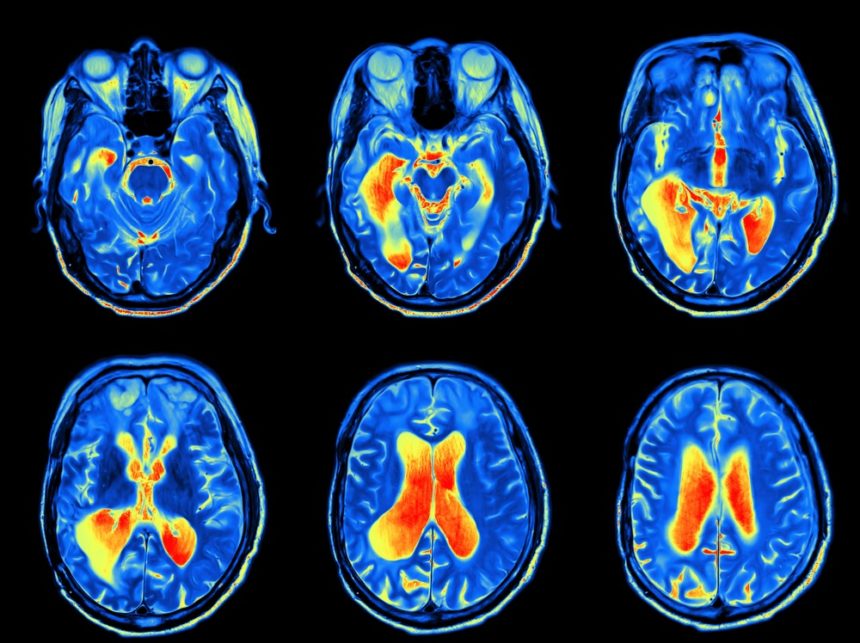
Need For Understanding Brain Functions, Introducing Medical Images - Brain, Heart and Hippocampus
Posted June 26, 2021 by Gowri Shankar ‐ 11 min read

Attribution and Counterfactuals - SHAP, LIME and DiCE
Posted June 19, 2021 by Gowri Shankar ‐ 10 min read
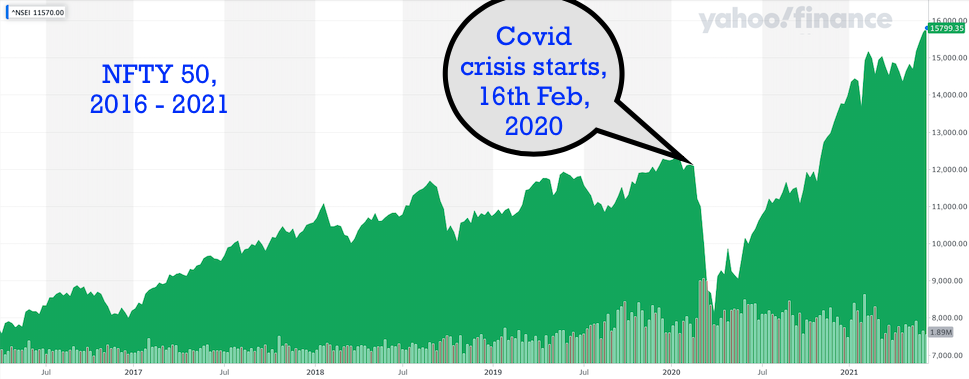
Is Covid Crisis Lead to Prosperity - Causal Inference from a Counterfactual World Using Facebook Prophet
Posted June 12, 2021 by Gowri Shankar ‐ 12 min read

La Memoire, C'est Poser Son Attention Sur Le Temps
Posted June 5, 2021 by Gowri Shankar ‐ 10 min read
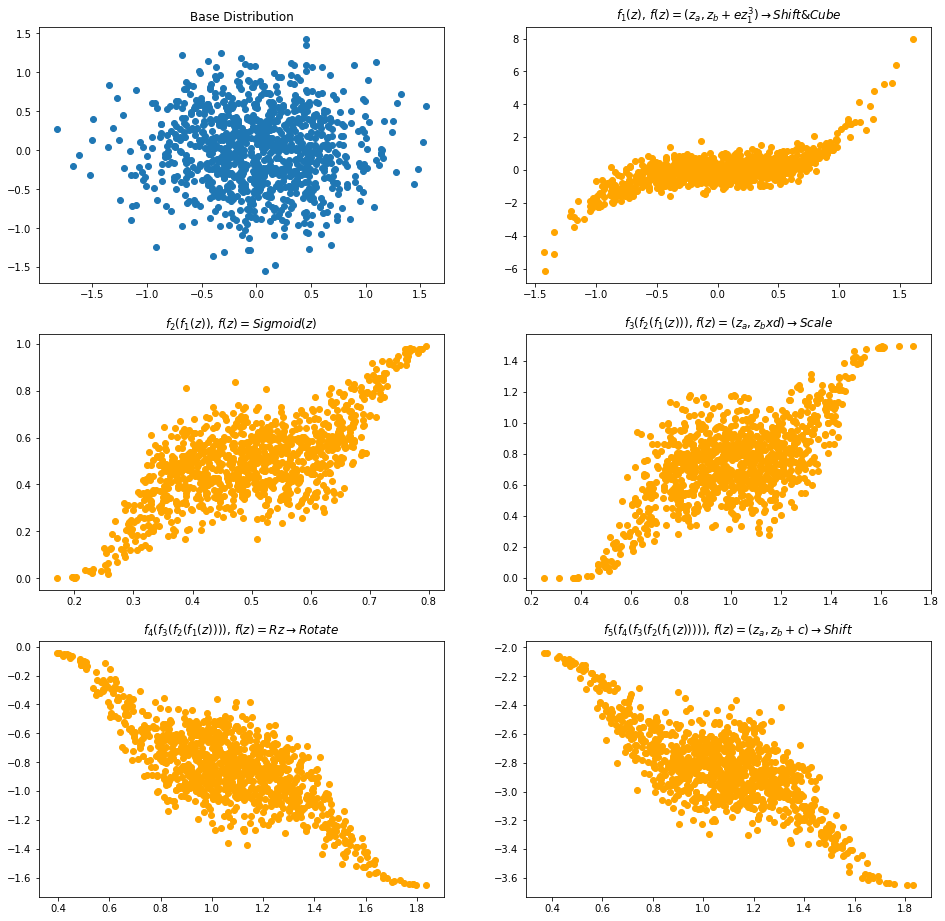
Normalizing Flows - A Practical Guide Using Tensorflow Probability
Posted May 29, 2021 by Gowri Shankar ‐ 9 min read
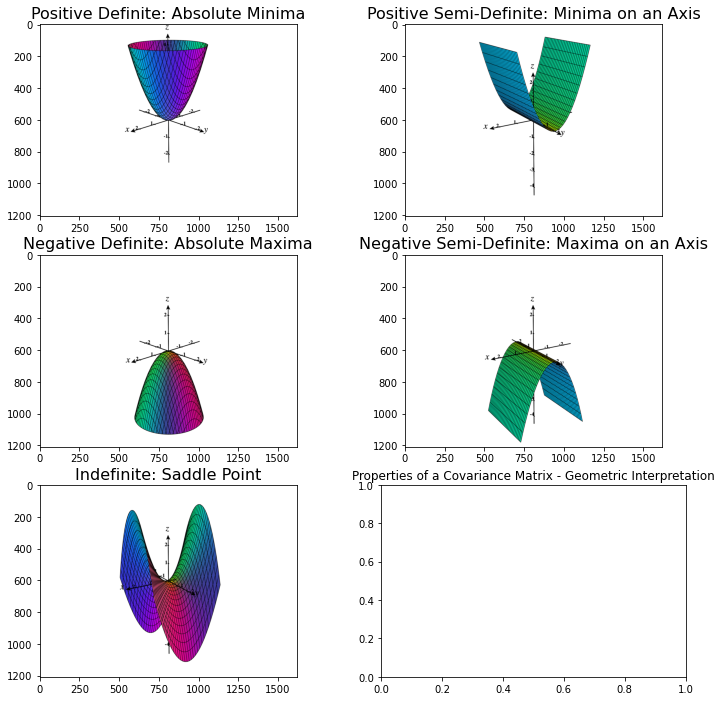
Why Covariance Matrix Should Be Positive Semi-Definite, Tests Using Breast Cancer Dataset
Posted May 23, 2021 by Gowri Shankar ‐ 8 min read
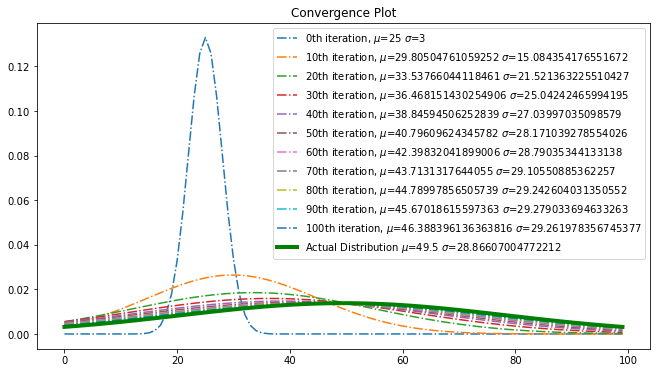
Calculus - Gradient Descent Optimization through Jacobian Matrix for a Gaussian Distribution
Posted May 15, 2021 by Gowri Shankar ‐ 12 min read
With 20 Watts, We Built Cultures and Civilizations - Story of a Spiking Neuron
Posted May 9, 2021 by Gowri Shankar ‐ 13 min read

Causal Reasoning, Trustworthy Models and Model Explainability using Saliency Maps
Posted May 2, 2021 by Gowri Shankar ‐ 9 min read

Higher Cognition through Inductive Bias, Out-of-Distribution and Biological Inspiration
Posted April 24, 2021 by Gowri Shankar ‐ 12 min read
Information Gain, Gini Index - Measuring and Reducing Uncertainty for Decision Trees
Posted April 17, 2021 by Gowri Shankar ‐ 9 min read

KL-Divergence, Relative Entropy in Deep Learning
Posted April 10, 2021 by Gowri Shankar ‐ 5 min read

Shannon's Entropy, Measure of Uncertainty When Elections are Around
Posted April 3, 2021 by Gowri Shankar ‐ 6 min read

Bayesian and Frequentist Approach to Machine Learning Models
Posted March 27, 2021 by Gowri Shankar ‐ 5 min read
Understaning Uncertainty, Deterministic to Probabilistic Neural Networks
Posted March 19, 2021 by Gowri Shankar ‐ 8 min read
Understanding Post-Synaptic Depression through Tsodyks-Markram Model by Solving Ordinary Differential Equation
Posted March 12, 2021 by Gowri Shankar ‐ 9 min read
Automatic Differentiation Using Gradient Tapes
Posted December 14, 2020 by Gowri Shankar ‐ 9 min read
Roll your sleeves! Let us do some partial derivatives.
Posted August 14, 2020 by Gowri Shankar ‐ 3 min read

GradCAM, Model Interpretability - VGG16 & Xception Networks
Posted July 4, 2020 by Gowri Shankar ‐ 11 min read

Tensorflow 2: Introduction, Feature Engineering and Metrics
Posted April 4, 2020 by Gowri Shankar ‐ 27 min read
Time and Space Complexity - 5 Governing Rules
Posted February 28, 2020 by Gowri Shankar ‐ 9 min read
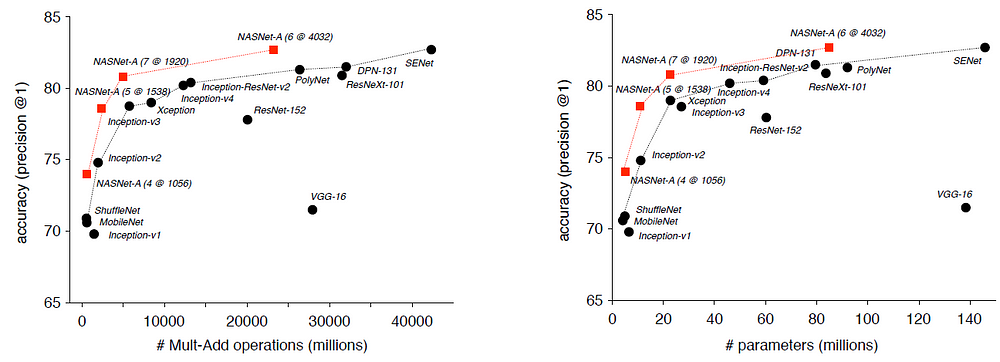
ResNet50 vs InceptionV3 vs Xception vs NASNet - Introduction to Transfer Learning
Posted June 28, 2019 by Gowri Shankar ‐ 22 min read